Data Models. The topic either elicits a "knowing nod" or a sense of "fear and desperation" for GIS professionals. Those who give a knowing nod have either spent some time creating or are intimately involved with using one. They might even be involved with data models with national or international implications. The rest of the population, from my experience, has a vague sense of what a data model is as well as some questions about how it affects GIS work. My hope is to make both groups more comfortable by taking a hard look at GIS data models: what they are, how they are changing the marketplace, how they are changing our day-to-day work, and what they may bring in the future.
What is a Data Model?
As users of geospatial technology, we model the world according to our own specific purposes. We might be interested in land management, site location, water network maintenance, or any one of the topics in the long list of applications for GIS. Each of us chooses how to model our data to fit the type of problem we are trying to solve, whether it be a raster or vector model, or a digital elevation model. Many of us mix and match the models. Some of us require built-in topology, while others do not. Some of us separate the spatial information and the database information. These are all "higher level" data model questions.
With GIS now thirty-odd years old, we are looking even more deeply at application-specific data models. Vendors, companies, schools, government agencies, and standards organizations are developing data models aimed at specific disciplines. Put simply, data models are structures into which data is placed. (A structure is a set of objects and the relationships between them.) The model ideally makes the work to be done using the GIS and its data "easier." ESRI puts it this way: "Our basic goals [in developing data models] are to simplify the process of implementing projects and to promote standards within our user communities."
Data models can detail everything from field names (e.g., "roads" vs. "streets"), the number of attributes for each geographic feature (e.g., 2 or 200), where network nodes are required, how relationships of connected linear features are indicated, and much more. Some are aimed at a single software platform (like ESRI's data models), while others are more broad, such as the Tri-Service's Spatial Data Standard (SDSFIE) for Facilities, Infrastructure, and Environment. (Tri-Service uses both the terms "standard" and "data model" to describe its products.)
Who Creates Data Models? And Why?
Data models come from many places. In the early days of GIS software, each implementer, likely working with its software vendor, developed its own model. For many years, some GIS software vendors have shared data models with users, either formally or informally. Some GIS users make their models available to other users. Sometimes industry organizations and government agencies tackle data models.
From my research I've found three reasons to develop data models: A GIS user (individual or group) develops a model to meet its organization's needs. A vendor might develop a model and make it available to its customers to help "jumpstart" their implementations. Industry organizations and government agencies craft models with the idea that they will simplify data sharing. There may be some mixed motives across those groups, so those statements may be oversimplified.
ESRI and Data Models
To get ESRI's take on data models I spoke with Steve Grise, Product Manager for Data Models. One of the things he illustrated when I asked about how standards play into data models was that most data models are built on standards. He pointed to the existing FGDC Cadastral Data Content Standard, which details what information "should be" included in such a GIS layer. That Standard is the basis of the ESRI parcel data model: the ESRI data model basically incorporates all of the definitions included in the FGDC standard. So, as Grise puts it, "They are exactly the same." What ESRI basically did was implement the standard in ArcGIS. Any other vendor or user can do the same.
I continued, by asking what benefit there is, if, for example, someone using MapInfo implements a model based on the FGDC Content Standard and someone else, using ESRI software, uses the ESRI implementation of the same standard? Are the two datasets more interoperable? The answer, according to Grise, is that such a model helps. Here's how: Consider that there is actually more than one type of parcel-ownership parcels (What land do I own?), and tax parcels (How does my land get taxed if some is agricultural and some residential?). The FGDC model details both types, so that hopefully, when two organizations share data, they can share the "right kind" of parcel information.
That brings up the annoying truth that nearly every local government calls its parcels something different - even if they are actually ownership parcels or tax parcels! That problem is something that organizations are addressing in their work on semantic (or information) interoperability. There is no magic here, but the solution is rather elegant. If there is a data content standard, (for example, the FGDC version that lays out a listing of all the different kinds of data one might have in that application area), it can be turned into a "reference schema," a "generic set of names" for the features. Then, each town can "map" its data names to the ones in the reference schema. If two towns have mapped to the "reference schema," then they can map to each other. This is something like the associative property of field names: if a=b and b=c, then a=c.
According to Grise, data models basically "simplify project implementation." Instead of everyone have to go back to the "deep philosophical roots" of how parcel data can be defined, GIS users can just get started knowing they are building on what's been learned in the past.
The history of ESRI's data model initiatives date back some six to eight years according to Grise. In a typical ESRI-user fashion, a well-put-together model for water utilities from Glendale, California, built on the version of ArcInfo that was current at the time, started to make the rounds to other users. That was the basis of the first formal ESRI data model, developed for water utilities. The project grew from there and now models-in various states of completion-are available for 21 application areas.

� 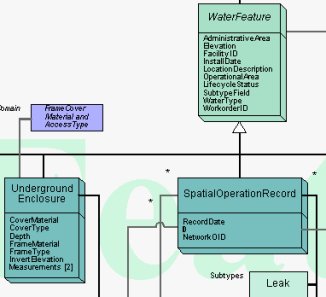 |
I asked Grise to sketch out how users take advantage of a data model in a project. The data model, which can be thought of as a long laundry list of potential objects and attributes for a particular use of GIS. ESRI's models are available in poster form-basically lots of arrows and boxes and lists of attributes. The team-ideally both those who will develop the model and those who will use it-work together to scratch out the parts that are not needed, and to add in those that are missing. I asked Grise if the model could be thought of as a type of "straw man." He replied "It's far easier to start with the front of the poster than the backside [the blank side]."
Next, the technical folks take the data model into the "back room" and perform the magic that transforms the data model from its generic form to the one illustrated in the marked up version. This version can then be loaded into ArcGIS, and small set of data can be loaded in as a prototype. Then, both data creators and end-users can review the data in the model to see if they are on track. An aside: ESRI has created tools so that once a geodatabase is created, users can print out their own poster of their data model. That is useful for explaining the model, but can also be used to "check" the created model against the marked-up version. There are also tools to extract, copy, and paste objects and tables from one data model into another.
We finished up our conversation by returning to standards. Grise suggests that the GIS community is still working to determine which standards are most important to address first. He points out that we are addressing content standards (FGDC), methods to store geometry (ISO), methods to encode data (ISO) and tools to enable Web Services (OGC and other organizations that deal with XML and SOAP). He suggests that we need to keep an eye on the problems that end-users are trying to solve and to try to approach those first. He suggests that the data content standards do have a direct impact, for example, while others are a bit out "in front" of potential users.
Intergraph and Data Models
Data models may seem like a "hot topic" these days, but David Holmes, director of worldwide product strategy, Intergraph Mapping and Geospatial Solutions, makes it clear that the company has been developing such models for 15 years, since MGE and FRAMME came on the scene. Intergraph has models for utilities and communications, local government, transportation, cartography, geospatial intelligence, and others.
Holmes and his colleagues Brimmer Sherman (vice president, Utilities & Communications), and Kecia Pierce, (industry consultant, Utilities & Communications), suggested a few reasons the topic seems to be "in the news" just now. The database focus of GIS (the trend toward storing both the spatial and non-spatial data in a standard database) may have helped rekindle interest, according to Sherman. The new connections with IT departments, which have always been active data modelers, may be a factor, too. Finally, the three suggested that the new players in the GIS market may just now realize the return on data models. It costs clients quite a lot of time/money for users to build from scratch, rather than beginning with a well-thought-out model.
What is new in the past few years, Holmes notes, is that the amount of intelligence in the data model is increasing. Gone are the "simple" points, lines, and polygons. Now the "data" holds information about objects' connectivity, symbology, and other properties. One key part of change - data models can now help prompt for correct data creation. So, for example, if a user wants to terminate a water line, the software will prompt the user with appropriate ways to do that, listing only the terminators that make sense in that situation.
That type of smart data model helps limit errors in data creation - assuming the model is built correctly. In the past, that type of intelligence was often held in the application software, or in the designer's head. I'll offer that this change may be part of the "data model renaissance" - now there is far more that can be modeled in the data. Said another way, the development of data models now may have a greater return on investment than in the past.
Pierce explained that Intergraph has a range of data model offerings that vary from discipline to discipline. QuickStart packages combine not only a data model, but also attribute definitions, relationships, reporting templates, sample queries, traces, and analysis tools - a sort of data model/application suite. The closer the users stay to the data model provided, she points out, the quicker they are up and running. Holmes explained that these complete packages are far more appropriate for sophisticated, centralized solutions, while sample "data model only" offerings serve the needs of decentralized users that are typically focused on desktop solutions.
Over the years Intergraph's sales and implementation teams have tweaked data models and collected and leveraged best practices. Today's models typically cover between 80 to 90 per cent of users' needs. In addition, Intergraph provides tools with its software to tweak the models further. As might be expected, some users make few changes, while others team up with third parties to update data models to their needs. For the largest of customers, it's not uncommon to tap Intergraph itself to craft the required model.
My sense, after speaking with the team from Intergraph, is that the goal is to make the data model as applicable to its user as possible. That's why Intergraph's transportation data model provides all six common linear reference system models, for example. Intergraph doesn't view the data model as a key piece of data sharing, that is done via underlying open systems - for example, an open API (application programming interface), and the use of standard databases. Those APIs will also let external systems look at the data model tables and structures.
How will the new and existing data models being offered and implemented impact the market? None of the Intergraph group felt a single physical standard that can be implemented would emerge. They noted differences in real world implementations that would preclude using similar physical models, even if the customers used software from the same vendor. Sherman noted that some consultants had developed data models and offered them for sale, with few takers. Similarly, he pointed out, the Tri-Service Data Model, while widely used inside the Tri-Service and federal government, was rarely used in industry.
End-users will have different relationships with data models, depending on their roles with the GIS. Those who work on operational tasks (daily updates, for example) will be rather far from the data model. Why? The application software will do the work of understanding the model and presenting it in a way aimed at performing those tasks. The end-user then can focus on the work, not on understanding the complexities below. Those performing more analytic, non-operational work, such as ad-hoc queries and "what if" scenarios, will need a better handle on the data model. The bottom line for both groups is the same, however: the data model is intended to make both sets of tasks easier.
The Open GIS Consortium and Data Models
To get a non-vendor perspective I spoke with Kurt Buehler, Chief Technical Officer of the Open GIS Consortium. (I am a consultant to that organization.) He made it clear that the Open GIS Consortium is only interested in one type of data models, ones that enhance interoperability.
OGC's work on data models dates back to its early years. One of the first outcomes of the Consortium was the development of a Spatial Schema, essentially the spatial data model upon which all others would be built. That model, now ISO 19107 (Spatial Schema) forms the basis of the OpenGIS Simple Feature Specification, the OpenGIS Geography Markup Language Implementation Specification and the Federal Geographic Data Committee's Framework Data Layers, among others.
�  |
The FGDC Data Content Standards are of particular interest because they are designed for exchange. And, the OGC, and other organizations have been involved in their deployment. The objectives of the Cadastral Data Content Standard, for example, include providing "common definitions for cadastral information found in public records, which will facilitate the effective use, understanding, and automation of land records," and "to standardize attribute values, which will enhance data sharing," and "to resolve discrepancies � which will minimize duplication within and among those systems."
The FGDC models which detail geometry and attribute structures are written in Unified Modeling Language, a language for writing data models. While very useful for people who do that type of work, it's not so valuable for those who implement models (say in a particular vendor's software package) or for any but the most accomplished programmers. To communicate the model effectively for its intended widespread usage, Buehler argues, there needs to be a simpler, easier-to-digest method of delivery. Buehler suggests that Geography Markup Language, GML, is a logical choice for sharing these models. Because it's open, published, and supported by many GIS vendors already, it should enhance uptake and use of the models.
Once a model is completed and available-in for example, GML-how is it used? The reference models play two important roles, one for those crafting their own models, and another for those organizations looking to make their data shareable to neighbors, states, commercial entities, and the National Spatial Data Infrastructure. Data model implementers can take the common model and use it as the basis of their own data models, developed for their own purposes.
If a transportation organization on a remote island in Puget Sound wants to tweak the FGDC model for its needs - perhaps removing some optional attributes that are not applicable, or including some geometries only used in its system, that is possible. If a vendor wants to use the model as the basis for a version in its data format, that is possible, too. The common data model acts as the starting point for these and other data model creators. And, as you might expect, the "closer" any implementation is to the reference the "easier" it will be to share data down the road.
For those who want to make data available for sharing, the data model plays a slightly different role. The data model is the basis for a translation capability, or "layer" (that can be implemented in many different ways), that will allow an organization's currently implemented data model to behave "as if" it is the reference model. Essentially, a layer sits between the current implementation and the rest of the Internet world. That layer makes the underlying model look and act as though it matches the reference data model exactly. And, if the organization looks across the Web at another organization that also implements such a solution, that organization's data will look and act as though it, too, is implementing the reference data model. Of course, behind the curtain, it could be whatever hardware, software, and custom data model the other organization selected to meet its needs.
In the United States, the vision down the road might look like this: Each of the 3000 counties hosts its own online GIS. (I chose counties for the purpose of illustration, but these could be built up from smaller or larger civil divisions, of course.) Each county selected a software package and a data model, to best meet its needs. If each county makes its data available "as though" it is in the reference data model, it would be relatively simple to write an application that knits two, or six, or a state, or even a nation's worth of data together in a single application. And since the data is accessed "live," it would be as up-to-date as the data held on the local county servers. Also important, those interested, who have permission, can work with the data, use it, and understand it, without creating a local copy. That should sound suspiciously like the NSDI vision.
What's Ahead?
This is an active time in the GIS data model world. The FGDC Data Content Standards are well along. So, too, are many of the vendor-offered data models. Will vendor models be widely implemented in user sites? Will the FGDC Standards enhance data sharing in the near future or long term? Is there friction between those trying to best serve their customers and those who envision NSDI? These are questions to ask in the coming months and years.
In the meantime, I'd like to gather some input from GIS end users on data models. Have you implemented a vendor-provided data model? How did it go? Did it "jump start" your implementation? What about the FGDC Content Standards? Are end-users following their development? Do you think either vendor-created data models or federal standards will impact your organization? How? Send me a few paragraphs with your experiences and predictions. I'll share some responses next week.










